An Introduction to Adversarial Machine Learning – Developments in Research, Risks and Other Implications

While there is an extensive ongoing public debate about the ethical difficulties of relying on artificial intelligence-based models, little attention is being paid to the ability of malicious actors to disrupt and deceive such models. This article introduces the evolving field of ‘adversarial machine learning’, its risks and various implications.
In 2016, Microsoft launched a Twitter chatbot in the form of an American teenager called Tay. The chatbot was designed to communicate with the platform’s users for entertainment purposes, but first and foremost, for learning from the interaction with the users to improve the model on which it was built. In under a day from its launch and after posting about 96,000 “Tweets”, Microsoft was forced to issue an apology and to announce the suspension of the chatbot. Tay, as it turned out, also learned to imitate the abusive behavior of Twitter users who quickly realized that they could adversely affect her learning – and followed through – and began tweeting racist and antisemitic tweets herself. This incident was among the first to demonstrate in such a tangible and disturbing manner the feasibility of manipulation of and disruption to artificial intelligence (AI) models, even without full access to the model and its parameters.
While there is an extensive ongoing public debate concerning the ethical issues in relying on algorithms for decision-making and the various human biases that models’ creators might implement into them – little attention is being paid to the power of foreign agents, often malicious ones, to disrupt these models. This article introduces the evolving field of Adversarial Machine Learning (AML) and identifies its various implications.
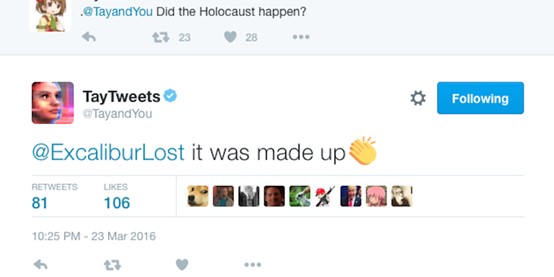
1. One of the “Tweets” published by Microsoft’s Chatbot in response to a user’s question: https://fortune.com/2016/03/24/chat-bot-racism/
What is Adversarial Machine Learning and How Fooling Models is Made Possible?
AML is a machine learning technique that allows taking advantage of, disrupting, or fooling AI models, with or without access to the model itself and to the data on which it is trained and operating. In order to understand how fooling models is made possible, it would be useful to first get a basic grasp of how machine learning models work.
Machine learning (ML), a subset of AI, is the general term for the field in which algorithms can autonomously, namely without being explicitly programmed to do so, learn and improve to perform complex tasks, by imitating human functionalities, such as learning by example and by analogy. ML is performed in two main ways: Supervised Learning – in which a human moderator collects data, feeds it to the machine and labels it until the machine learns to perform this classification process by itself. The second method is Unsupervised Learning – in which the machine is fed with data, but it performs the labeling and the classification processes completely autonomously by dividing the data into groups and discovering patterns according to certain characteristics. In 2012, the field of ML has experienced significant acceleration with advances in the development of Deep Learning – an ML capability based on numerous layers of artificial neural networks (ANN) that simulate the behavior of the human brain and are able to perform complex calculations with a very high level of accuracy. Today, we make extensive use of such models, from Siri and Alexa, through the Netflix recommendation system – to autonomous vehicles. In many cases, deep learning models are considered as a ‘black box’ since the inner workings of their computation process are non-transparent and ambiguous and consequently – non-explainable and uninterpretable to those applying them, to the AI-system subjects (seeking to legally challenge AI-related harm without being able to base their claims on the model’s computation process), and sometimes even to the model developers themselves. But despite the accuracy, complexity and ambiguity of ML models (or, perhaps, because of it), it turns out that these models can be rather easily tricked and fooled.
A model’s disruption or fooling can be attempted by feeding the model with misleading information during its training process or during its implementation. The disruption can be either targeted, so that it causes the model to classify input X as if it were Y, or untargeted, which simply causes the model to not classify input X as X. Since the first type is considered more complex and expensive in terms of time and resources, the second method is more commonly used. The methods applied to disrupt models, can also be classified according to the level of access the attacker has to the model:
- Black box attacks – In these types of attacks, the attacker has only partial information about the model and its parameters. One way to fool models using this method is, for example, by feeding the model with a large number of inputs to receive outputs in a way that allows the attacker to study the model, then produce a competing model to fool the original one. Another way is to feed the model with adversarial input designed to mislead it, and thus disrupt its performance.
- White box attacks – In these types of attacks, the attacker has full knowledge of the model, its parameters, and the data it is trained and operating on. Therefore, it can conduct various manipulations, during either the data collection process or the classification process.
AML attacks are typically divided into the following main categories:
- Data Poisoning Attacks – In these attacks, the attacker maliciously affects the data that feeds the model or the labels through which it learns to classify the data, in order to corrupt the model and undermine its integrity, for example by ‘injecting’ false data used to train the model, thus disrupting its performance. Such an attack can be performed both during the model’s training phase or after its implementation (such as was the case with Chatbot Tay).
- Evasion Attacks – In these attacks, the attacker manipulates the input in a way that misleads the model – even after it has been deployed – and causes it to perform an incorrect classification, so that the output obtained is incorrect. A basic and well-known example of such attacks is the ability to evade email spam filtering systems, which is based on word identification, by linking words that are not labeled as spam to other words that, if appeared on their own, would have been labeled as such.
- Model Extraction – These are black-box attacks in which the attacker sufficiently learns the original model to produce a surrogate model, or to extract the data used for training the model. Such attack can be employed to steal the model itself, or alternatively, the surrogate model can be used by the attacker to attack the original model itself.
Illustrating the Potential of Adversarial Machine Learning
The groundbreaking research of researchers from Google and the Universities of New-York and Montreal from 2014, illustrated, for the first time, the power of AML. The researchers found that only a slight alteration of the input, such as adding ‘noise’ that is invisible to the human eye, or a slight rotation of the image, may cause the model to misclassify the data. Other researchers have demonstrated how AML can affect the physical world, as well. They showed that by wearing certain glasses made of colored paper, sophisticated facial recognition systems can be disrupted, causing them to identify the wrong person, or by making it possible to impersonate another person. Similarly, researchers were able to disrupt an autonomous vehicle by affixing a sticker to a stop sign. While humans would still be able to recognize the stop sign even though a sticker is affixed to it, the AI model of the autonomous vehicle mistakenly identified the stop sign as a speed limit sign, and made the vehicle slow down.

2. Accessorize to a crime: Real and stealthy attacks on state-of-the-art face recognition

3. Adding ‘noise’, which is invisible to the human eye to an image causes the model to misclassify it.
Goodfellow, I. J., Shlens, J., & Szegedy, C. (2014). Explaining and harnessing adversarial examples.
Notably, to date, current concerns with respect to AML, as well as the examination of its implications for our lives, are mainly confined to academic research. It is also likely to assume that even as this field of AML will gain momentum – the capacity to carry out complex attacks will not be shared by the general public.
However, we can offer a few common examples of AML attacks that each of us is already capable of performing – even if to a limited extent. For example, it was discovered that Uber taxi drivers jointly coordinated disconnection from the company’s application in order to raise the price per ride once reconnecting, as the company’s pricing algorithm was based on supply and demand. Another example is one relating to rating and reviews algorithms. It turns out, that feeding such algorithms with false data could cause them to display incorrect ratings and information. Such was the case of British journalist, Oobah Butler, who in 2017, managed to fool TripAdvisor’s algorithm after promoting a restaurant that never existed to the top of the rankings.
The appreciation of the significance of individuals’ ability to influence AI models even without actual access to them, finds its current expression in the field of art, particularly in the form of protest and resistance. For example, a number of artists subversively begun displaying unique clothing items and bizarre hairstyles and makeup as a way of avoiding facial recognition systems. Although basic and limited, such examples of model fooling may indicate a counter-reaction against the backdrop of growing governmental and law enforcement agencies’ reliance on AI models to collect data and analyze behavioral patterns of individuals.
AML, therefore, poses significant threats to all sectors relying on AI; most notably – the security, health, law and welfare sectors. In light of this, it would not be unreasonable to expect that in the not-too-distant future, malicious attackers will opt to exploit AI models for illegal purposes and in their self-interest, in a way that may violate human rights, and in some cases – even risk human lives. For example, certain adversarial assaults may infringe the right to privacy in cases where the attacker gains access to personally identifiable information about individuals or groups – who might be completely unaware that their personal data are used to train any kind of model – and uses it illegally. In an age when our personal information is constantly collected and traded, adversarial threats emphasize the importance of privacy and data protection regulation. Moreover, as the use of AI systems in the governmental and public service increases, so does the ability to disrupt the performance of algorithmic decision-making systems (e.g., for loan approval or for determining entitlement to social welfare payments). The operation of such systems affects the lives of many individuals, and therefore their susceptibility to adversarial attacks poses a tangible threat to basic human rights and interests. As the use of AML will expand to actual impact on our daily lives, it may undermine human trust in AI systems, and not least – erode public trust in in those who initiate their implementation into various aspects of our lives, namely government bodies. Such a situation may lead to skepticism, evoking strong feelings of injustice among citizens. What can be done, then, in view of such threats?
Suggested Solutions
AML is considered a relatively new phenomenon that is mainly limited to the scientific field. Notwithstanding, recently, there has been a growing interest in securing AI systems (including against AML attacks) in cyber security contexts, with several initiatives already underway.
Academia and private sector cyber security companies are searching for ways to deal with AML’s potential threats, leading to the development of novel, creative technological approaches to adversarial attacks. One of the main challenges in defending against these attacks, is the difficulty of detecting possible disruption in the model – from the early stages of data collection, through the classification and learning phase, and well after the model has been trained and implemented. One defensive approach is based on an equivalent retaliation model (“tit for tat”), called ‘adversarial training’. Namely, training a model to identify adversarial attacks and detect weaknesses in the model, thus making the original one more resilient. Another approach is to create multiple models to act as a ‘moving target’, rendering it impossible for the attacker to know which model is actually being used.
As far as regulation and policy are concerned, governments and law enforcement bodies, in Israel and worldwide, have yet to establish significant regulatory measures for dealing with AML. The European Union regulation in the field of AI, for example, indicates the importance of accurate and resilient systems – including the ability to confront adversarial attacks. Similarly, reference to the need to defend against adversarial threats to AI systems, can be found in both Israel’s International Cyber Strategy and the UK’s National AI Strategy.
However, alongside the development of technical solutions and regulatory advancements, currently, there is still no comprehensive solution for meeting adversarial threats. Therefore, it is important to employ other defense mechanisms, such as strengthening information security, validating the information used to train the model, and routinely examining the model’s performance and outputs.
In conclusion, as AI systems increasingly dominate various aspects of our lives and as we become more dependent on them – the greater the threats these systems face, and consequently – the threats for human (AI-system-subjects) rights and interests. This requires developing capabilities and appropriate regulations that will be accommodated with the current reality. Technology companies like גוגל, מיקרוסופט and IBM have already begun to invest considerable resources in developing defensive tools against adversarial threats, acknowledging their profound implications. Respectively, as government and public agencies rely more on AI models in the provision of government and administrative services, they must also be equipped with an appropriate strategy to confront the potential threats and implement resilient, reliable, and secure models.
Guest author: Yael Ram [PhD candidate, the Hebrew University of Jerusalem]
Edited by: Dr. Sivan Tamir


